Paralelní výpočty
Paralelní výpočty jsou v dnešním mnohajádrovém světě, kte cluster, cloud, GPU, multi-threading apod. jsou všude, téměř nevyhnutelné. Python nám nabízí nemálo možností pro jejich využítí. Existují ovšem i některá zásadní omezení.
Kdy (a jak) paralelizovat¶
Ještě více než pro optimalizaci platí pro paralelizaci, že vždy paralelizujeme jen po předchozí analýze funkčního (sekvenčního) programu a jen nutné části programu. Navíc se vždy snažíme využít (trapně) jednoduchých paralelismů (embarrassingly parallel) v našem programu.
Vlákna v (C)Pythonu¶
CPython má pro vícevláknové (multi threading) aplikace jedno velice zásadní omezení ve formě GIL - Global Interpreter Lock. Ten existuje proto, že CPython interpret jako takový není vláknově bezpečný. Neznamená to ovšem, že vlákna jsou v (C)Pythonu absolutní tabu. Zmiňme předně, že např. Jython nebo stále oblíbenější PyPy jsou vláknově bezpečné(ější). I CPython může vlákna používat, existují tam nakonec moduly threading a thread. Přímočaře můžeme vlákna použít, pokud náš program obsahuje nějaké blokující input/output (I/O) operace. Takovou operaci lze nechat běžet ve vlákně a spustit při tom jiné vlákno. Navíc, pokud programujeme Python modul v C, lze GIL uvolnit manuálně a více využít vláken.
Vlákna v NumPy a SciPy¶
NumPy a SciPy sice běží pouze v CPythonu (existuje sice NumPyPy, v současnosti je ale stále nekompletní), dokáží ale právě GIL ve správnou chvíli uvolnit a některé výpočty provádět ve více vláknech současně, viz http://wiki.scipy.org/ParallelProgramming. Např. maticový součin (dot) toho využívá. Navíc často volají numerické knihovny (BLAS, LAPACK, případně jejich optimalizované verze ATLAS nebo Intel MKL).
%load_ext Cython
import numpy as np
import matplotlib.pyplot as plt
from IPython.display import Image
Cython.parallel¶
cython.parallel je poněkud nenápadný modul, který ale ovšem využít vlákna (pomocí OpenMP) poměrně jednoduše. Musíme ovšem pracovat pouze s daty (tj. s proměnnými) a funkcemi mimo CPython interpret. Pak můžeme uvolnit gil, např. pomocí with nogil bloku a v něm použít prange, tak jako to děláme v následujícím příkladě.
Budeme jednoduše sčítat matice. Výpočet jednoduše paralelizujeme tak, že řádky se mohou sčítat nezávisle. To nám zařídí prange. Také si všimněte, že výsledné pole alokujeme předem, což může pro velká pole přinést další zrychlení.
Pozor, při kompilaci musíme použít -fopenmp, jinak se vlákna budou ignorovat.
%%cython -f --compile-args=-fopenmp --link-args=-fopenmp
cimport cython
from cython.parallel import parallel, prange, threadid
# import cython.parallel as parallel
import numpy as np
cimport numpy as np
# bez kontroly velikosti polí
@cython.boundscheck(False)
# bez relativního indexování pomocí záporných indexů
@cython.wraparound(False)
cpdef double[:,:] add_arrays_2d_views(double[:,:] buf1, double[:,:] buf2, double[:,:] output=None, int nthreads=2):
cdef int x, y, inner, outer
# tuto proměnnou budeme potřebovat v nogil bloku
cdef int _nthreads = nthreads
# zkontrolujeme rozměry, jinak hrozí segmentation fault
assert buf1.shape[0] == buf2.shape[0]
assert buf1.shape[1] == buf2.shape[1]
outer = buf1.shape[0]
inner = buf1.shape[1]
if output is None:
output = np.zeros_like(buf1)
else:
assert output.shape[0] == buf1.shape[0]
assert output.shape[1] == buf1.shape[1]
with nogil, cython.boundscheck(False), cython.wraparound(False):
for x in prange(outer, schedule='static', num_threads=_nthreads):
for y in xrange(inner):
output[x, y] = (buf1[x, y] + buf2[x, y])
return output
Funkci se nám (doufejme) podařilo implementovat vícevláknově. Bylo to ale za cenu přece jenom nemalé práce navíc, přestože Cython nám práci výrazně zjednodušuje. Je třeba poznamenat, že tato funkce by byla v čistém C obdobně složitá.
Otestujeme vytvořenou funkci pro středně velká pole.
n = 2**13
X = np.random.rand(n, n)
Y = np.random.rand(n, n)
Z = np.zeros_like(X)
Pro jistotu i kontrola správnosti výpočtu.
np.allclose(X+Y, add_arrays_2d_views(X, Y))
Změříme čas pro 1, 2 a 4 vlákna. Měli bychom vidět zrychlení, záleží na procesoru, arhitektuře, kompilátoru apod.
%timeit add_arrays_2d_views(X, Y, Z, nthreads=1)
%timeit add_arrays_2d_views(X, Y, Z, nthreads=2)
%timeit add_arrays_2d_views(X, Y, Z, nthreads=4)
Multiprocessing¶
Python obsahuje vestavěnou knihovnu multiprocessing, která poskytuje podobné služby jako vlákna, místo vláken ovšem používá procesy. To má své výhody i nevýhody. Výhodou je jednoduchost a bezpečnost -- pokud spadne jeden proces, ostatní mohou běžet dál. Hlavní nevýhodou (i když z hlediska bezpečnost je to výhoda) jsou oddělené paměťové prostory. (Pokud samozřejmě nepoužijeme sdílenou paměť na úrovni operačního systému.) To znamená, že je třeba co nejméně mezi procesy komunikovat. Ideálně se tato architektura hodí na map-reduce algoritmy, které jsme už zmínili dříve ve funkcionálním programování.
Ukážeme si multiprocessing na velice jednoduchém příkladu, kde procesy se budou pouze identifikovat.
import multiprocessing
import os
%%file my_tasks.py
import os
def task(args):
return os.getpid(), args
import my_tasks
my_tasks.task("test")
pool = multiprocessing.Pool(processes=4)
result = pool.map(my_tasks.task, range(1, 9))
result
ipyparallel (dříve IPython parallel)¶
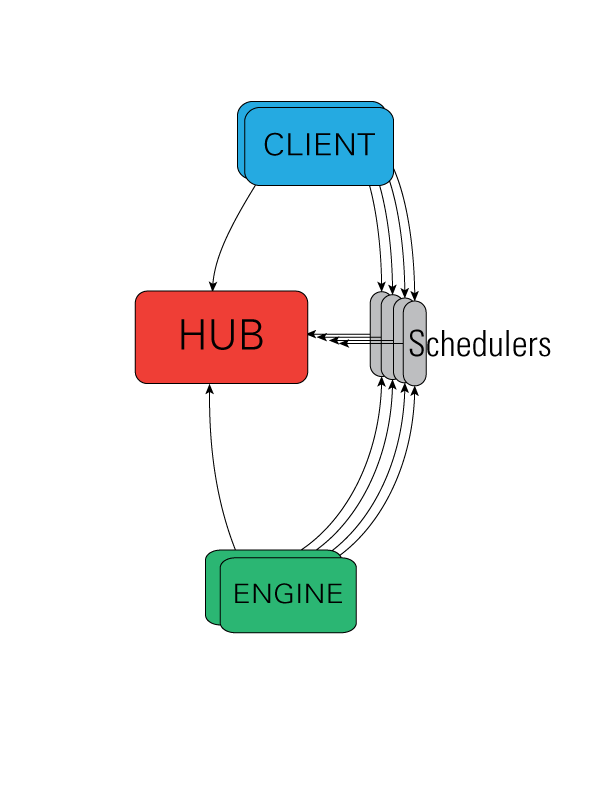
Ipython nám přináší (jak je jeho dobrým zvykem) velice užitečný a všestranný nástroj na paralelní výpočty, který se navíc snadno používá. S použitím message passing a technologie, která byla vyvinuta pro Qt konzoli a následně notebook, přidává ipyparallel ještě scheduler a hub, které ovládají a komunikují s klienty a jednotlivými Python procesy (engine).
Startujeme cluster¶
Abychom mohli začít tento nástroj používat, musíme nastartovat procesy, ve kterých se budou provádět výpočty. Nejjednodušší je to pomocí nástroje ipcluster (ten se spouští v konzoli, nikoli v Pythonu)
$ ipcluster start -n 4
To nám spustí 4 procesy na jednom počítači. Případně můžeme použít IPython Dashboard -- úvodní stránky Jupyter Notebook. IPython cluster můžeme spustit i na více počítačích, a to pomocí ssh, mpi, různých batch systémů (PBS, Torque apod.). Můžeme použít i Amazon EC2.
Používáme cluster¶
Jakmile jsme nastartovali cluster, můžeme ho začít používat z našeho Python programu. K tomu slouží třída IPython.parallel.Client.
from ipyparallel import Client
cli = Client()
Pomocí atributu ids se můžeme dozvědět, jaké prostředky máme k dispozici.
cli.ids
Každý z těchto procesů můžeme přímo použít pro spuštění nějaké úlohy. Zkusme nejdřív zjistit id procesu z pohledu operačního systému.
def getpid():
""" return the unique ID of the current process """
import os
return os.getpid()
getpid()
Nyní můžeme stejný příkaz spustit na jednom vzdáleném procesu pomocí metody apply_sync.
cli[0].apply_sync(getpid)
Velice jednoduše můžeme to samé udělat pro celý cluster.
cli[:].apply_sync(getpid)
cli[:] nám vlastně vytvořilo objekt DirectView, jakýsi (přímý) pohled na cluster. Pro paralelní spuštění můžeme např. použít metodu map_sync, což je obdoba multiprocessing.Pool.map.
dview = cli[:]
dview.map_sync(lambda x: x**10, range(16))
Můžeme použít i dekorátory parallel a remote. Definujeme teď funkci, která čeká danou dobu (to nám nahradí nějaký delší výpočet).
@dview.parallel(block=True)
def dummy_task(delay):
""" a dummy task that takes 'delay' seconds to finish """
import os, time
t0 = time.time()
pid = os.getpid()
time.sleep(delay)
t1 = time.time()
return [pid, t0, t1]
dview.parallel dekorátor způsobil, že dummy_task má metodu map, která spustí funkci paralelně na množinu vstupů. Použití je následující.
# Vygenerujeme několik náhodných časů
delay_times = numpy.random.rand(4)
# a můžeme použít map
dummy_task.map(delay_times)
Vidíme, že jsme dostali množinu výsledků, které byly spočítány v různých procesech.
Pojďme zkusit vizualizovat zatížení jednotlivých procesů. Použijeme k tomu více vstupů a jednoduchou funkci, která vytvoří jednoduchý graf.
def visualize_tasks(results):
res = numpy.array(results)
fig, ax = subplots(figsize=(10, res.shape[1]))
yticks = []
yticklabels = []
tmin = min(res[:,1])
for n, pid in enumerate(numpy.unique(res[:,0])):
yticks.append(n)
yticklabels.append("%d" % pid)
for m in numpy.where(res[:,0] == pid)[0]:
ax.add_patch(Rectangle((res[m,1] - tmin, n-0.25),
res[m,2] - res[m,1], 0.5, color="green", alpha=0.5))
ax.set_ylim(-.5, n+.5)
ax.set_xlim(0, max(res[:,2]) - tmin + 0.)
ax.set_yticks(yticks)
ax.set_yticklabels(yticklabels)
ax.set_ylabel("PID")
ax.set_xlabel("seconds")
delay_times = numpy.random.rand(64)
results = dummy_task.map(delay_times)
visualize_tasks(results)

Tady vidíme, že jsme poměrně dobře vytížili všechny čtyři procesy pomocí poměrně jednoduché paralelizace. Ještě lepšího výsledku můžeme dosáhnout pomocí LoadBalancedView. Tato třída, na rozdíl od DirectView, rozděluje úlohy dynamicky podle zatížení jednotlivých procesů.
LoadBalancedView dostaneme jednoduše pomocí load_balanced_view:
lbview = cli.load_balanced_view()
Nyní definujeme stejnou funkci jako dummy_task, jen pomocí LoadBalancedView dekorátoru.
@lbview.parallel(block=True)
def dummy_task_load_balanced(delay):
""" a dummy task that takes 'delay' seconds to finish """
import os, time
t0 = time.time()
pid = os.getpid()
time.sleep(delay)
t1 = time.time()
return [pid, t0, t1]
A zkusíme opět nakreslit graf využití procesorů.
result = dummy_task_load_balanced.map(delay_times)
visualize_tasks(result)

Vidíme, že jsme rovnoměrněji zatížili náš cluster a dasáhli o něco kratšího celkového času pro výpočet.
Více najdete v dokumentaci¶
ipyparallel nabízí ještě mnohem více, např.
- paralelní triky (
%pxapod.) - asynchronní (neblokující) spouštění
- použití MPI
- ..., viz https://ipyparallel.readthedocs.io/
MPI¶
Pro intenzivní komunikaci mezi procesy je třeba použít efektivnějšího řešení, než je komunikace přes IPython controller, kterou jsme doposud používali (aniž bychom o tom nějak více přemýšleli). K tomu účelu obvykle slouží MPI -- Message Passign Interface. MPI je nezávislé na programovacím jazyce, neboť se jedná především o síťový protokol, který umožňuje synchronně nebo asynchronně posílat několik primitivních tipů, a to buď mezi jednotlivými procesy (point to point) nebo hromadně (broadcasting). Implementací je více, mezi běžné patři např. MPICH nebo OpenMPI. Pro Python existuje mpi4py.
Jednoduchý příklad¶
MPI programy je třeba spouštět pomocí mpirun. Následující příklady se tedy pro názornost nespouští přímo v notebooku, i když IPython přímé použití MPI také podporuje.
%%file mpitest.py
from mpi4py import MPI
from numpy import arange
comm = MPI.COMM_WORLD
rank = comm.Get_rank()
if rank == 0:
# rank 0 je ridici proces
data = ["a", 2.0, 3.0, {"numpy": arange(3)}]
print("sending data: {}".format(data))
comm.send(data, dest=1, tag=11)
elif rank == 1:
# tady bychom provadeli jednotlive vypocty
data = comm.recv(source=0, tag=11)
print("received data: {}".format(data))
print("rank {} finished".format(rank))
Spustíme pomocí mpirun se dvěma procesy.
!mpirun -n 2 python mpitest.py
Jak jsme viděli, pomocí send můžeme posílat celkem libovolné Python obejkty. Výstup posledního řádku může být přeházený, neboť procesy běží paralelně. Komunikace pomocí send je blokující, pro neblokující bychom použili isend.
%%file mpitest_async.py
from mpi4py import MPI
from numpy import arange
comm = MPI.COMM_WORLD
rank = comm.Get_rank()
print("rank {} started".format(rank))
if rank == 0:
# rank 0 je ridici proces
data = ["a", 2.0, 3.0, {"numpy": arange(3)}]
print("sending data: {}".format(data))
req = comm.isend(data, dest=1, tag=11)
req.Wait()
elif rank == 1:
# tady bychom provadeli jednotlive vypocty
data = comm.recv(source=0, tag=11)
print("received data: {}".format(data))
print("rank {} finished".format(rank))
!mpirun -n 2 python mpitest_async.py
Posílání polí apod.¶
send dokáže poslat téměř cokoli, může to ale být neefektivní. Proto existují funkce Send and Recv (ano, rozdíl je pouze ve velikosti prvních písmen), které dokáží posílat bloky primitivních datových typů. To se velice hodí pro numpy, kde jsou pole uložené právě v takových blocích. Pozor, tady sestupujema na nižší úroveň abstrakce (podobně jako u Cythonu) a musíme daleko více explicitně řešit typy, rozměry, alokace apod.
Pojďme se podívat, jak lze pomocí Send a Recv poslat numpy pole. Pro numpy pole základních typů můžeme použít automatické rozeznání tohoto typu.
%%file numpy_mpi.py
# from http://mpi4py.scipy.org/docs/usrman/tutorial.html#point-to-point-communication
from mpi4py import MPI
import numpy
comm = MPI.COMM_WORLD
rank = comm.Get_rank()
print("rank {} started".format(rank))
# pass explicit MPI datatypes
if rank == 0:
data = numpy.arange(1000, dtype='i')
comm.Send([data, MPI.INT], dest=1, tag=77)
elif rank == 1:
data = numpy.empty(1000, dtype='i')
comm.Recv([data, MPI.INT], source=0, tag=77)
# automatic MPI datatype discovery
if rank == 0:
data = numpy.arange(100, dtype=numpy.float64)
print("rank {}, sum={}".format(rank, data.sum()))
comm.Send(data, dest=1, tag=13)
elif rank == 1:
data = numpy.empty(100, dtype=numpy.float64)
comm.Recv(data, source=0, tag=13)
print("rank {}, sum={}".format(rank, data.sum()))
print("rank {} finished".format(rank))
!mpirun -n 6 python numpy_mpi.py
Další možnosti¶
Blaze -- blíží se nové NumPy?¶
Blaze se snaží rozšířit NumPy (nebo spíše vytvořit nové) o paralelní výpočty, heterogenní rozměry, různě uložená data aj. Dokumentace říká
"Blaze is the next generation of NumPy, Python’s extremely popular array library. Blaze is designed to handle out-of-core computations on large datasets that exceed the system memory capacity, as well as on distributed and streaming data.
Blaze will allow analysts and scientists to productively write robust and efficient code, without getting bogged down in the details of how to distribute computation, or worse, how to transport and convert data between databases, formats, proprietary data warehouses, and other silos.
The core of Blaze consists of generic multi-dimensional Array and Table objects with an associated type system for expressing all kinds of data types and layouts, especially semi-structured, sparse, and columnar data. Blaze’s generalized calculation engine can iterate over the distributed array or table and dispatch to low-level kernels specialized for the layout and type of the data."
from blaze import Data
t = Data([(1, 'Alice', 100),
(2, 'Bob', -200),
(3, 'Charlie', 300),
(4, 'Denis', 400),
(5, 'Edith', -500)],
fields=['id', 'name', 'balance'])
t
t[t.balance < 0]
", ".join((m for m in dir(t) if not m.startswith("_")))
import pyopencl as cl
import numpy
import numpy.linalg as la
a = numpy.random.rand(50000).astype(numpy.float32)
b = numpy.random.rand(50000).astype(numpy.float32)
ctx = cl.create_some_context()
queue = cl.CommandQueue(ctx)
mf = cl.mem_flags
a_buf = cl.Buffer(ctx, mf.READ_ONLY | mf.COPY_HOST_PTR, hostbuf=a)
b_buf = cl.Buffer(ctx, mf.READ_ONLY | mf.COPY_HOST_PTR, hostbuf=b)
dest_buf = cl.Buffer(ctx, mf.WRITE_ONLY, b.nbytes)
prg = cl.Program(ctx, """
__kernel void sum(__global const float *a,
__global const float *b, __global float *c)
{
int gid = get_global_id(0);
c[gid] = a[gid] + b[gid];
}
""").build()
prg.sum(queue, a.shape, None, a_buf, b_buf, dest_buf)
a_plus_b = numpy.empty_like(a)
cl.enqueue_copy(queue, a_plus_b, dest_buf)
print(la.norm(a_plus_b - (a+b)), la.norm(a_plus_b))
Python + Intel Many Integrated Core Architecture¶
Intel Many Integrated Core Architecture (MIC) je procesor podobný GPU s x86 instrukcemi. Nedávno byl uceden do prodeje první generace pod názvem Xeon Phi. Zdá se, že Python se podařilo na této architektuře zkompilovat: http://software.intel.com/en-us/forums/topic/392736. V takovém případě lze používat např. vestavěný modul multiprocessing.
...¶
Další najdete na https://wiki.python.org/moin/ParallelProcessing.
Komentáře
Comments powered by Disqus